Table des matières
Un guide de lecture sur le Deep Learning avec CNNs
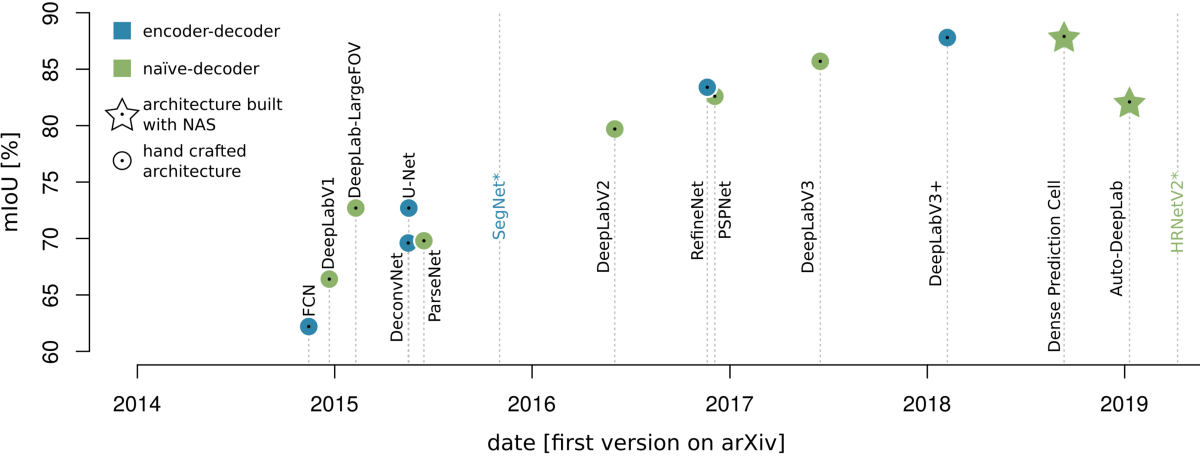
L’évolution de la famille DeepLab est caractéristique de l’évolution des modèles inspirés du FCN pour la segmentation d’images. Les variantes de DeepLab peuvent être trouvées dans les modèles à décodeur naïf et à codeur-décodeur. Par conséquent, le guide s’oriente sur cette famille en examinant d’abord les décodeurs naïfs, puis en se tournant vers les modèles codeur-décodeur.
Modèles à décodeur naïf
Les informations les plus importantes des modèles de décodage naïf sont principalement la mise en place de convolutions dites atreuses et l’exploitation du contexte d’image à longue portée pour la prédiction au niveau des pixels. Les convolutions atreuses sont une variante des convolutions normales, qui permettent un champ récepteur croissant sans pour autant la perte de résolution d’image. Le célèbre module Atrous Spatial Pyramid Pooling (Module ASPP) dans DeepLab-V2 [4] et plus tard combine les deux: atroces convolutions et exploitation du contexte d’image à longue portée. Lors de la lecture de la littérature suivante, concentrez-vous sur les développements de ces fonctionnalités – Atrous convolutions, le module ASPP et l’exploitation / l’analyse syntaxique du contexte d’image à longue portée.
Modèles codeur-décodeur
L’encodeur-décodeur le plus célèbre aujourd’hui est probablement le U-Net [5]. Un CNN développé pour l’analyse d’images médicales. Sa structure claire a invité de nombreux chercheurs à l’expérimenter et à l’adopter et il est célèbre pour ses connexions à sauts, qui permettent le partage de fonctionnalités entre les chemins codeur et décodeur. Les modèles codeur-décodeur se concentrent sur l’amélioration des cartes de caractéristiques sémantiquement riches lors du suréchantillonnage dans le décodeur avec des cartes de caractéristiques plus localement précises de l’encodeur.
Avec la littérature à portée de main, vous serez en mesure de réfléchir sur les documents de segmentation d’images modernes et les implémentations avec les CNN. Rencontrons-nous à nouveau dans la partie III, où nous discuterons de la détection d’objets.
[1] Hoeser, T; Kuenzer, C. Détection d’objets et segmentation d’images avec apprentissage en profondeur sur les données d’observation de la Terre: revue-partie I: évolution et tendances récentes. Télédétection 2020, 12 (10), 1667. DOI: 10.3390 / rs12101667.
[2] Long, J .; Shelhamer, E .; Darrell, T. Réseaux entièrement convolutifs pour la segmentation sémantique. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 39, 640–651.
[3] Chen, L.C .; Zhu, Y .; Papandreou, G .; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision – ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C .; Weiss, Y., Eds .; Springer International Publishing: Cham, Suisse, 2018; pp. 833–851
[4] Chen, L.C .; Papandreou, G .; Kokkinos, I .; Murphy, K .; Yuille, A.L. DeepLab: Segmentation d’image sémantique avec des réseaux convolutionnels profonds, convolution atreuse et CRF entièrement connectés. IEEE Trans. Pattern Anal.
Mach. Intell. 2016, 40, 834–848.
[5] Ronneberger, O .; Fischer, P.; Brox, T. U-Net: Réseaux convolutifs pour la segmentation d’images biomédicales. En informatique médicale et intervention assistée par ordinateur – MICCAI 2015; Navab, N., Hornegger, J.,
Wells, W.M., Frangi, A.F., Eds .; Springer International Publishing: Cham, Suisse, 2015; pp. 234-241.