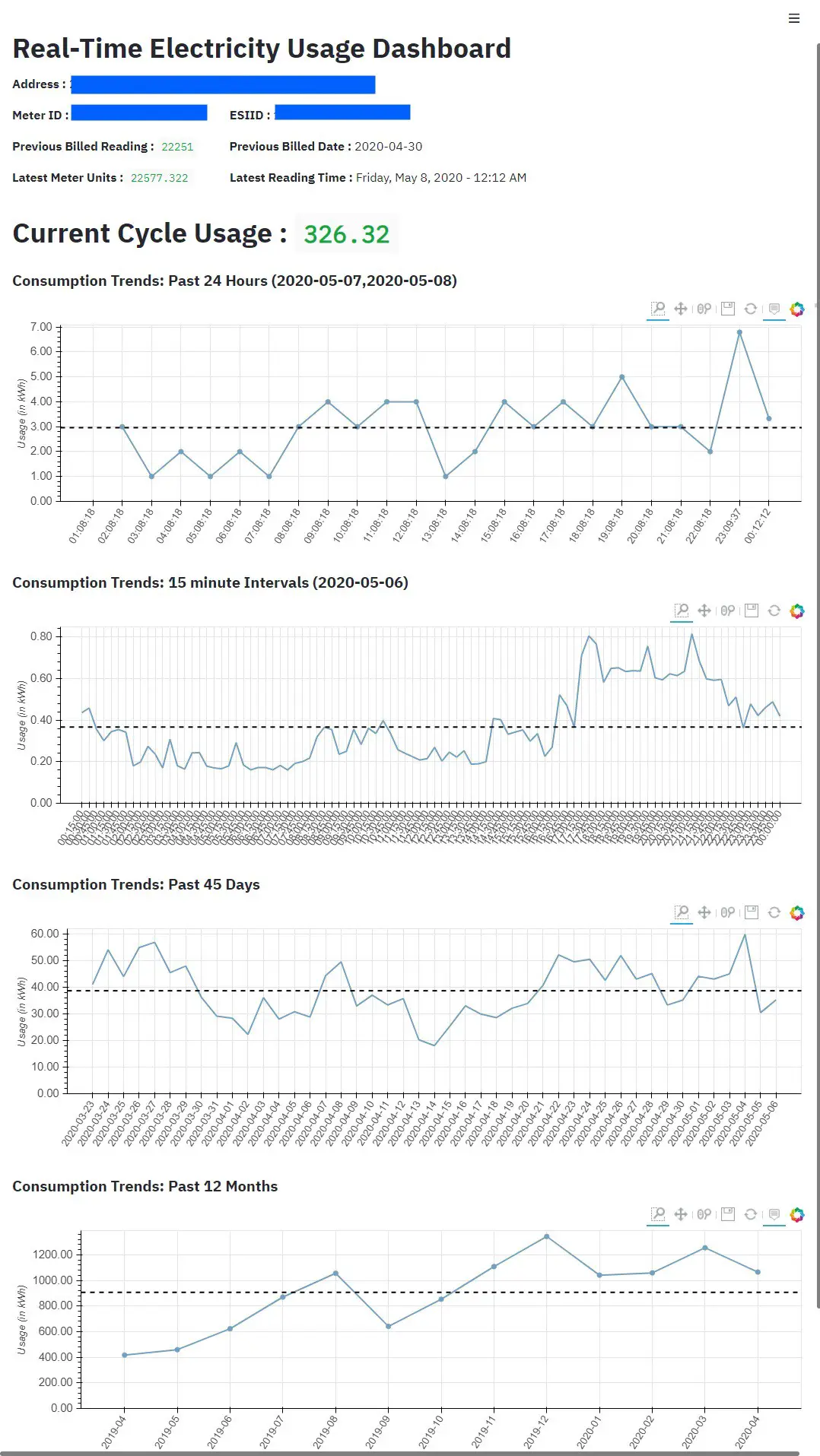
Surveillance en temps réel de la consommation d’électricité
Cdéfis: En suivant le mantra des développeurs, j’ai commencé par chercher sur Google pour voir les travaux précédents déjà effectués dans ce domaine. Je suis tombé sur quelques référentiels travaillant avec smart-meter-texas, mais tous étaient démolition Web projets.
Je ne suis pas un grand fan de la façon dont le Web-scrapping d’acquérir des points de données car ils ne sont pas fiables, évolutifs et sont susceptibles de rompre avec les nouveaux changements d’interface utilisateur effectués par l’hôte. J’ai passé beaucoup d’heures dans le mode développeur de mon navigateur safari. J’ai pu retracer les appels d’authentification et par la suite tous les appels effectués par le site Web vers ses serveurs principaux.
Défi 1: Les demandes à l’API ont simplement été ignorées car elles n’ont pas été faites à partir du navigateur et du portail smartmeter.
Solution 1: J’ai dû me moquer des en-têtes de demande pour répliquer le navigateur comme ci-dessous:
{
«Agent utilisateur’:‘ Mozilla / 5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit / 537.36 (KHTML, ’’ comme Gecko) Chrome / 77.0.3865.90 Safari / 537.36 ’,
«Origine’:‘ Https://www.smartmetertexas.com»,
}
Défi 2: J’essayais de faire des appels POST similaires aux API en utilisant le même ensemble de paramètres (en-têtes + corps + point de terminaison) en utilisant le module de requêtes de python, mais je n’ai pas pu m’authentifier. Cela était dû au fait que le site Web utilise des cookies pour gérer son flux. J’ai essayé de désactiver les autorisations du navigateur pour les cookies et le smartmetertexas.com ne se chargeait pas.
Solution: J’ai dû utiliser Requêtes → Module Sessions pour gérer les cookies. Ici, je lance un premier appel au portail pour récupérer les cookies en lui faisant croire que la demande entrante provient d’un navigateur Web. Je définirais ensuite les mêmes cookies lors des appels à l’API d’authentification. Ces étapes sont clairement visibles ici sur le repo github.
Après avoir résolu les problèmes d’authentification, j’ai pu appeler différents points de terminaison de l’API pour récupérer les différents points de données. Cela couvre la partie d’ingestion de données. Passons aux visualisations.
réfrêne: La construction du tableau de bord était un autre défi majeur. Les raisons étant principalement mon manque de compétences frontales. J’ai essayé de faire un cas d’utilisation sur Tableau Desktop / Public, Power BI, etc. et je n’ai pas pu opter pour l’un d’eux car tous sont marqués avec un facteur de prix qui ne rendrait plus ce budget de projet gratuit.
Le choix du tableau de bord devait être prétentieux car je voulais que cet utilitaire soit un outil léger. Nous avons cherché à exécuter cette application sur un ordinateur monocarte. Chargement d’un logiciel lourd sur le OS raspbian ralentirait le système et chaufferait la carte mère.
À la rescousse est venu le cadre purement basé sur python, rapide et facile à utiliser appelé Streamlit.
Le cadre d’ingestion de données stocke tous les fichiers de données pour les tendances au format CSV, ce qui facilite la formation de Pandas Dataframe dessus.
Streamlit fournit un moyen très rapide et efficace de tracer les graphiques et les visualisations. Le tableau de bord initial était opérationnel au cours des premières heures de développement du tableau de bord.
De plus, Streamlit ouvre un port sur l’ordinateur au réseau auquel il est connecté et partage un lien accessible par tous les autres appareils du réseau. Ainsi, ce tableau de bord est désormais accessible sur les appareils mobiles et les appareils informatiques de tous mes colocataires. La mobilité est définitivement une cerise sur le gâteau.
Voici à quoi ressemble la configuration chez moi: