Intelligence artificielle
-

Auto-Docs pour Python – Vers la science des données
Auto-Docs pour Python – Vers la science des données De cela, nous pouvons voir qu’il existe plusieurs structures clés que nous devons être en mesure d’extraire de notre code, à savoir: Docstrings: (contenant des descriptions, des paramètres, des paramètres de type, etc.) ce sont les sections de citation de bloc que nous utilisons pour décrire…
-

Analyse des sentiments par courrier électronique à l’aide de Python et de Microsoft Azure – Partie 1
Analyse des sentiments par courrier électronique à l’aide de Python et de Microsoft Azure – Partie 1 photo par Markus Spiske sur Unsplash #Assign Body column to new objectemail_body = email_data[‘Body’]#Display top 5 rows and the overall length of the seriesprint(email_body.head())print(‘n’)print(« Starting email count: »,email_body.shape) #Removing r and n characters from stringsemail_body = email_body.str.replace(« r », » »)email_body = email_body.str.replace(« n », » »)#Display top…
-

Définition de la valeur P pour tout le monde
Définition de la valeur P pour tout le monde Expliquons la valeur P avec un peu plus de contexte en fournissant un exemple: photo par Rai Vidanes sur Unsplash Disons que vous êtes un boulanger qui vient de recevoir une nouvelle cargaison de miel brut. Mais voici le hic, vous n’avez même jamais entendu parler…
-

Expériences d’apprentissage One Shot avec perte de quadruplet
Expériences d’apprentissage One Shot avec perte de quadruplet Un de mes amis dit que, pour faire des progrès significatifs dans l’apprentissage automatique, il faut lire les documents de recherche sur le terrain. En parcourant les articles de recherche, j’ai trouvé celui-ci « Au-delà de la perte de triplets: un réseau quadruplet profond pour la ré-identification des…
-

Raclage Web et prétraitement pour la PNL
Raclage Web et prétraitement pour la PNL Utilisation de Python pour extraire et traiter les données texte du Web Continuer la lecture sur Vers la science des données »
-

Explorer le prédicteur de mot suivant! – Dhruvil Shah
Explorer le prédicteur de mot suivant! – Dhruvil Shah Comment le clavier de votre téléphone sait-il ce que vous souhaitez saisir ensuite? La prédiction de langue est une application de traitement du langage naturel – PNL qui s’intéresse à la prédiction du texte donné dans le texte précédent. Les réponses automatiques ou suggérées sont des…
-

5 concepts à connaître sur la descente de gradient et la fonction de coût
5 concepts à connaître sur la descente de gradient et la fonction de coût Gradient Descent est un algorithme d’optimisation itératif utilisé dans l’apprentissage automatique pour minimiser une fonction de perte. La fonction de perte décrit la performance du modèle compte tenu de l’ensemble actuel de paramètres (poids et biais) et la descente de gradient…
-

LinkedIn Open Sources un petit composant pour simplifier l’interopérabilité TensorFlow-Spark
LinkedIn Open Sources un petit composant pour simplifier l’interopérabilité TensorFlow-Spark Spark-TFRecord permet le traitement des structures TFRecord de TensorFlow dans Apache Spark. Source: https://towardsdatascience.com/get-started-with-apache-spark-and-tensorflow-on-azure-databricks-163eb3fdb8f3 L’interopérabilité de TensorFlow et d’Apache Spark est un défi courant dans les scénarios d’apprentissage automatique du monde réel. TensorFlow est sans doute le cadre d’apprentissage en profondeur le plus populaire du…
-

Structuration des blocs-notes Jupyter pour des expériences d’apprentissage machine rapides et itératives
Structuration des blocs-notes Jupyter pour des expériences d’apprentissage machine rapides et itératives Une feuille de triche pour les praticiens de ML occupés qui ont besoin d’exécuter rapidement de nombreuses expériences de modélisation dans un espace de travail Jupyter bien rangé. Contrairement au monde du logiciel, le terme «composant réutilisable» peut être difficile à appliquer dans…
-
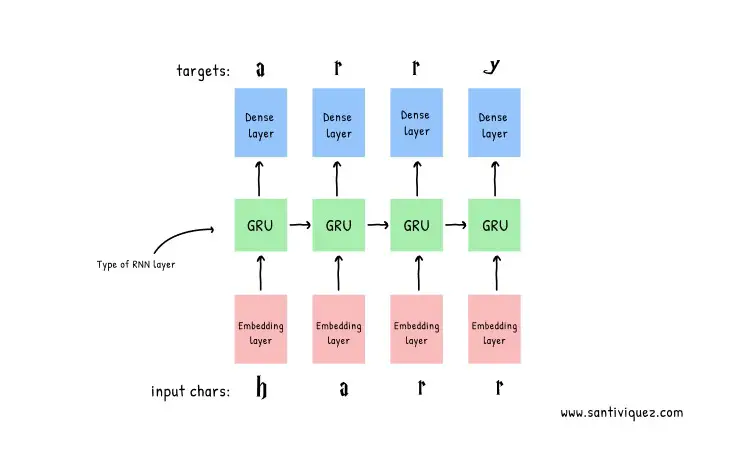
Harry Potter et l’expérience d’apprentissage en profondeur
Harry Potter et l’expérience d’apprentissage en profondeur Pour chaque caractère, le modèle recherche l’incorporation, exécute le GRU un pas de temps avec l’incorporation en entrée et applique la couche dense pour générer des logits prédisant la probabilité de log du caractère suivant. ¹ Il y a trois ans (à l’époque où enseigner aux RNN à…